Modul 3
Security Architecture
Cel
Po tym module masz rozumieć, jak projektować bezpieczne środowisko, a nie tylko znać nazwy urządzeń i technologii. Architektura bezpieczeństwa odpowiada na pytania:
- gdzie umieścić kontrolę
- co odseparować
- jak ograniczyć skutki awarii lub kompromitacji
- jak chronić dane w różnych stanach
- jak dobrać model infrastruktury do ryzyka, kosztu, dostępności i możliwości odtwarzania.
Po module powinieneś umieć:
- porównać on-premises, cloud i hybrid
- wyjaśnić shared responsibility model w chmurze
- odróżnić virtualization, containerization, serverless i microservices
- rozumieć specyficzne ryzyka Internet of Things (IoT), Industrial Control Systems (ICS), Supervisory Control and Data Acquisition (SCADA), Real-Time Operating System (RTOS) i embedded systems
- zaprojektować prostą segmentację
- dobrać właściwe urządzenie bezpieczeństwa do scenariusza
- dobrać metodę ochrony danych do ich typu i stanu
- odróżnić high availability, disaster recovery, backup i resilience
- rozumieć RTO i RPO jako pojęcia, które wrócą w module zarządzania ryzykiem.
Wprowadzenie
Architektura bezpieczeństwa to sposób, w jaki układasz systemy, sieci, dane, kontrole i procesy, aby całość była trudniejsza do zaatakowania, łatwiejsza do monitorowania i bardziej odporna na awarie.
W Security+ pytanie architektoniczne często wygląda tak: firma ma określone ograniczenia — koszt, chmurę, system legacy, wymóg dostępności, dane regulowane albo konieczność pracy zdalnej — i musisz wybrać najlepszy projekt. Nie chodzi wtedy o „najmocniejsze narzędzie”, tylko o rozwiązanie najlepiej pasujące do scenariusza.
Wyjaśnienie
1. Modele architektury: on-premises, cloud i hybrid
Problem
Organizacja musi zdecydować, gdzie utrzymywać systemy: we własnym centrum danych, w chmurze, czy w modelu mieszanym. Każdy model zmienia koszty, odpowiedzialności, ryzyka, sposób wdrażania kontroli i możliwość odtwarzania po awarii.
Wyjaśnienie od podstaw
On-premises oznacza środowisko utrzymywane lokalnie przez organizację: własne serwery, własna sieć, własna serwerownia lub centrum danych. Organizacja ma dużą kontrolę, ale też dużą odpowiedzialność za sprzęt, zasilanie, chłodzenie, fizyczne bezpieczeństwo, aktualizacje i kopie zapasowe.
Cloud, czyli chmura, oznacza korzystanie z zasobów dostawcy: mocy obliczeniowej, pamięci, usług aplikacyjnych, baz danych lub platform. Chmura daje elastyczność, skalowalność i szybkie wdrażanie, ale wymaga zrozumienia odpowiedzialności między klientem a dostawcą.
Hybrid, czyli model hybrydowy, łączy on-premises i cloud. Przykład: firma trzyma system finansowy lokalnie, ale używa chmury do backupu, aplikacji webowej albo analityki.
Oficjalne cele SY0-701 wskazują cloud, hybrid considerations, third-party vendors, on-premises, centralized vs decentralized, virtualization, containerization, IoT, ICS/SCADA, RTOS, embedded systems i high availability jako elementy architektury, które trzeba porównywać w kontekście bezpieczeństwa.
Jak to działa krok po kroku
Organizacja identyfikuje wymagania: bezpieczeństwo, koszt, skalowalność, zgodność, dostępność.
Wybiera model: lokalny, chmurowy albo hybrydowy.
Określa, kto odpowiada za poszczególne warstwy: sprzęt, sieć, system, aplikację, dane, tożsamość.
Projektuje kontrole: segmentację, IAM, szyfrowanie, monitoring, backup, logging.
Testuje odporność i procesy odtwarzania.
Regularnie aktualizuje architekturę, bo ryzyko i wymagania zmieniają się w czasie.
Przykład praktyczny
Mała firma przenosi pocztę i pliki do chmury, ale zostawia lokalny system magazynowy, bo jest stary i trudno go przenieść. To tworzy środowisko hybrydowe. Firma musi zabezpieczyć integrację między lokalną siecią i chmurą, konta użytkowników, synchronizację tożsamości, logi, backup oraz dostęp administratorów.
Przykład egzaminacyjny
Scenariusz
Firma chce szybko skalować aplikację sezonową, ale musi utrzymać część danych w lokalnym centrum danych z powodów regulacyjnych. Jaki model najlepiej pasuje?
Najlepsza odpowiedź:
Hybrid cloud, ponieważ łączy lokalne utrzymanie części zasobów z elastycznością chmury.
Z czym nie mylić
Nie myl chmury z automatycznym bezpieczeństwem. Dostawca chmury zabezpiecza część infrastruktury, ale klient nadal odpowiada za konfigurację, tożsamości, dane, uprawnienia, sieciowe reguły dostępu i wiele ustawień usług.
Typowe błędy
Najczęstszy błąd to przeniesienie systemu do chmury bez zmiany sposobu zarządzania. Chmura wymaga kontroli konfiguracji, monitoringu, zarządzania tożsamością, tagowania zasobów, automatyzacji i kontroli kosztów. Drugi błąd to brak jasnej odpowiedzialności za backup i odzyskiwanie.
Definicja do zapamiętania
On-premises daje największą bezpośrednią kontrolę, cloud daje elastyczność i skalowalność, a hybrid łączy oba modele, ale zwiększa złożoność integracji i odpowiedzialności.
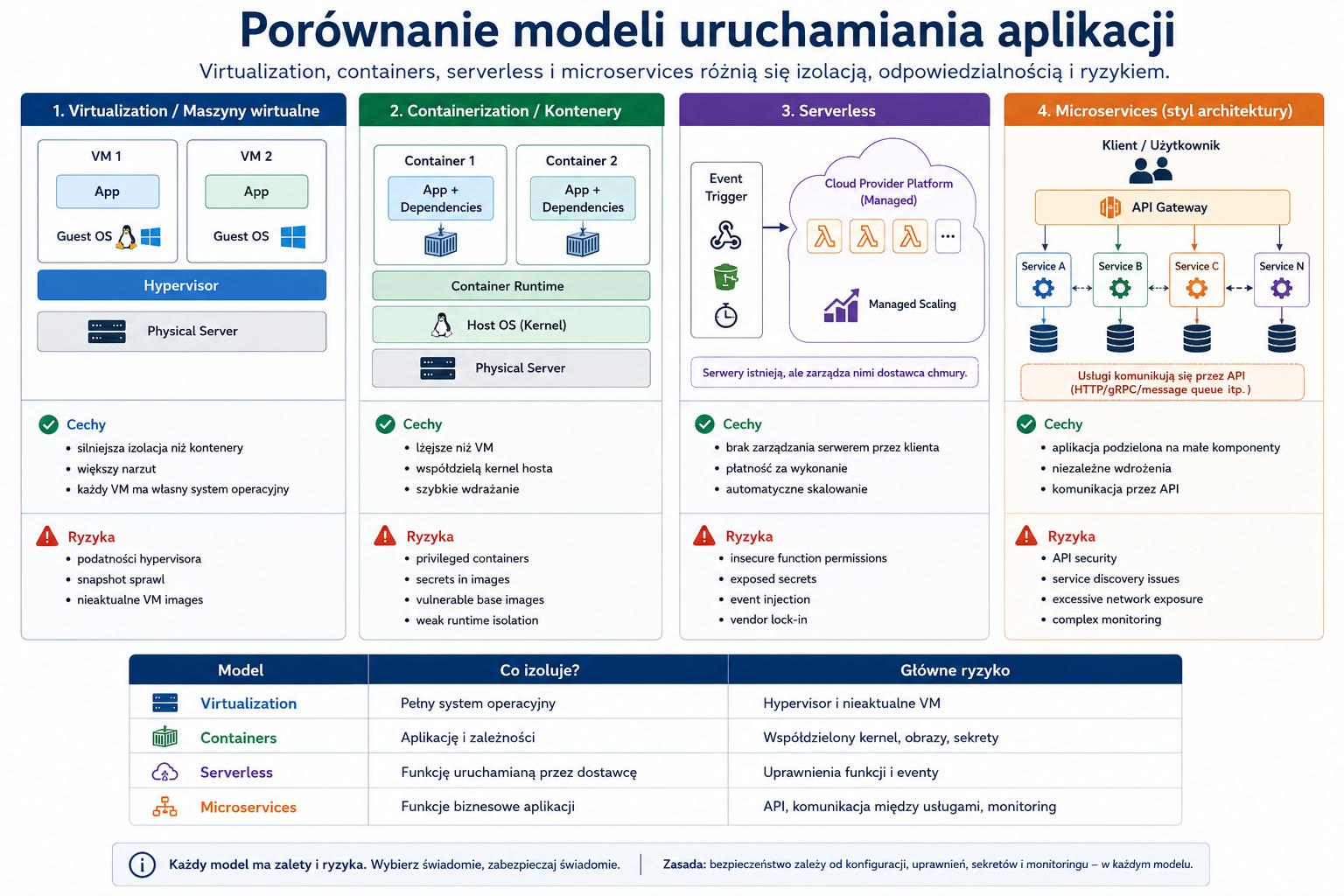
3. Virtualization, containerization, serverless i microservices
Problem
Nowoczesne środowiska nie składają się tylko z fizycznych serwerów. Aplikacje działają na maszynach wirtualnych, w kontenerach, jako funkcje serverless albo zestawy mikroserwisów. Każdy model daje korzyści, ale ma inne ryzyka.
Wyjaśnienie od podstaw
Virtualization pozwala uruchamiać wiele maszyn wirtualnych na jednym fizycznym hoście. Każda maszyna ma własny system operacyjny. Ryzykiem jest m.in. źle zabezpieczony hypervisor, nadmierne uprawnienia administracyjne i możliwość wpływu jednej maszyny na zasoby hosta.
Containerization uruchamia aplikacje w kontenerach, które współdzielą jądro systemu gospodarza, ale mają własne środowisko wykonawcze. Kontenery są lżejsze niż maszyny wirtualne, ale wymagają ochrony obrazów, rejestrów, sekretów, konfiguracji i orkiestracji.
Serverless oznacza, że programista wdraża funkcję lub logikę, a dostawca zarządza dużą częścią infrastruktury wykonawczej. Ryzyka przesuwają się w stronę uprawnień funkcji, konfiguracji zdarzeń, sekretów, logowania i zależności.
Microservices to podejście, w którym aplikacja jest podzielona na wiele mniejszych usług. Daje elastyczność, ale zwiększa liczbę połączeń, interfejsów Application Programming Interface (API), zależności i punktów monitorowania.
Jak to działa krok po kroku
Organizacja wybiera model uruchamiania aplikacji.
Dzieli odpowiedzialności między infrastrukturę, platformę i aplikację.
Zabezpiecza obrazy, konfiguracje, sekrety i połączenia.
Ogranicza uprawnienia każdej usługi lub funkcji.
Monitoruje komunikację między komponentami.
Automatyzuje wdrożenia i kontrolę konfiguracji.
Przykład praktyczny
Aplikacja sklepu internetowego może składać się z mikroserwisu koszyka, płatności, wysyłki i kont użytkowników. Jeśli każdy mikroserwis ma zbyt szeroki dostęp do bazy danych, kompromitacja jednego komponentu może zagrozić całemu systemowi. Lepsze podejście to ograniczenie uprawnień, segmentacja, osobne sekrety, monitoring API i kontrola komunikacji między usługami.
Przykład egzaminacyjny
Scenariusz
Firma chce szybko wdrażać małe funkcje bez zarządzania serwerami, ale musi uważać na uprawnienia funkcji i sekrety. Który model opisuje scenariusz?
Najlepsza odpowiedź:
Serverless.
Z czym nie mylić
Kontener nie jest tym samym co maszyna wirtualna. Maszyna wirtualna ma własny system operacyjny, a kontener zwykle współdzieli jądro hosta. Serverless nie oznacza, że „nie ma serwerów”; oznacza, że klient nie zarządza nimi bezpośrednio.
Typowe błędy
Częsty błąd to uruchamianie kontenerów z nadmiernymi uprawnieniami. Drugi błąd to przechowywanie sekretów w obrazach kontenerów lub kodzie. Trzeci błąd to brak skanowania obrazów i zależności.
Definicja do zapamiętania
Virtualization izoluje pełne systemy operacyjne, containerization izoluje aplikacje lżej, serverless ukrywa zarządzanie serwerami, a microservices dzielą aplikację na wiele małych usług.
4. IoT, ICS, SCADA, RTOS i embedded systems
Problem
Nie wszystkie systemy są klasycznymi laptopami i serwerami. Urządzenia przemysłowe, czujniki, sterowniki, kamery, systemy kontroli dostępu i urządzenia Internet of Things często mają ograniczone zasoby, długi cykl życia i trudności z aktualizacją.
Wyjaśnienie od podstaw
Internet of Things (IoT) to urządzenia podłączone do sieci, które zbierają dane lub wykonują działania: kamery, czujniki, inteligentne zamki, urządzenia medyczne, systemy HVAC.
Industrial Control Systems (ICS) to systemy sterujące procesami przemysłowymi.
Supervisory Control and Data Acquisition (SCADA) to systemy nadzorujące i zbierające dane z procesów przemysłowych, np. energetyki, produkcji lub infrastruktury.
Real-Time Operating System (RTOS) to system operacyjny zaprojektowany do reakcji w przewidywalnym czasie. Występuje często w systemach wbudowanych i przemysłowych.
Embedded systems to systemy wbudowane w urządzenia, które wykonują wyspecjalizowane funkcje.
Jak to działa krok po kroku
Urządzenie wykonuje funkcję fizyczną lub pomiarową.
Łączy się z siecią albo systemem zarządzania.
Często działa przez wiele lat.
Aktualizacje mogą być trudne, ryzykowne lub niedostępne.
Bezpieczeństwo wymaga segmentacji, ograniczenia dostępu, monitoringu, kontroli dostawców i bezpiecznej konfiguracji.
W środowiskach przemysłowych dostępność i bezpieczeństwo fizyczne mogą być ważniejsze niż szybkie patchowanie.
Przykład praktyczny
Fabryka ma system SCADA sterujący linią produkcyjną. Nie można go restartować w dowolnym momencie, bo zatrzymanie linii kosztuje dużo pieniędzy. Zamiast natychmiastowego patchowania w środku dnia, organizacja może użyć segmentacji, kontroli dostępu, monitoringu, okna serwisowego i testów zmian.
Przykład egzaminacyjny
Scenariusz
Organizacja ma urządzenia przemysłowe, których nie można często aktualizować. Jaka kontrola architektoniczna jest szczególnie ważna?
Najlepsza odpowiedź:
Segmentacja sieci, ograniczenie dostępu i monitoring jako kontrole zmniejszające ryzyko.
Z czym nie mylić
Nie traktuj IoT i ICS tak samo jak laptopów pracowników. Zasady są podobne, ale ograniczenia są inne: brak agenta EDR, brak częstych restartów, ograniczone aktualizacje, zależność od dostawcy i potencjalny wpływ na bezpieczeństwo fizyczne.
Typowe błędy
Częsty błąd to podłączanie urządzeń IoT do tej samej sieci co systemy krytyczne. Drugi błąd to pozostawianie domyślnych haseł. Trzeci błąd to brak inwentaryzacji urządzeń.
Definicja do zapamiętania
IoT, ICS, SCADA, RTOS i embedded systems wymagają szczególnej architektury bezpieczeństwa, bo często są trudne do aktualizacji, mają długi cykl życia i mogą wpływać na procesy fizyczne.
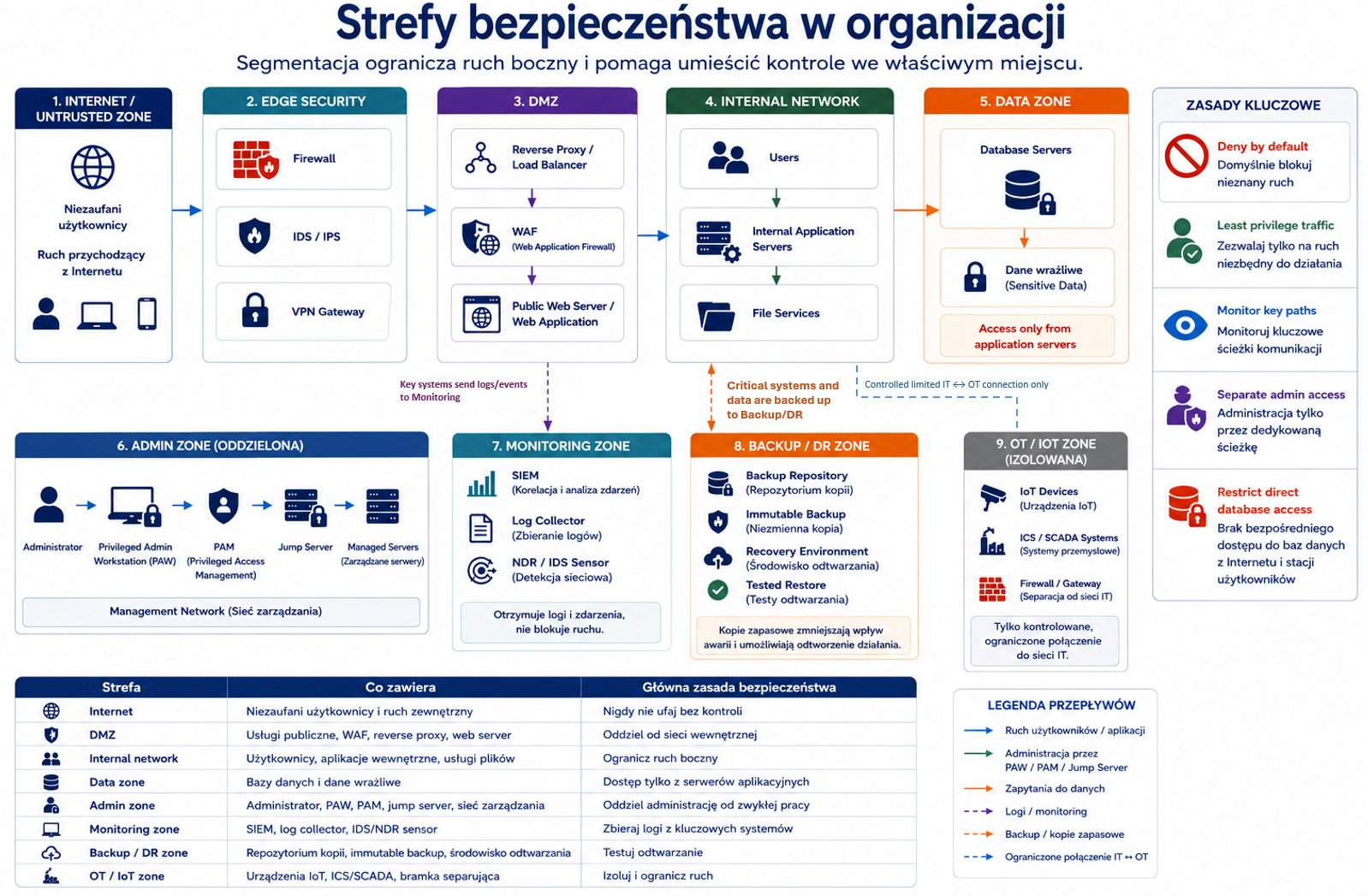
5. Segmentacja, security zones, air gap i SDN
Problem
Jeśli cała sieć jest płaska, kompromitacja jednego hosta może szybko rozprzestrzenić się na inne systemy. Segmentacja ogranicza ruch, zmniejsza skutki ataku i ułatwia monitoring.
Wyjaśnienie od podstaw
Segmentacja to podział środowiska na części o różnych poziomach zaufania, funkcjach lub ryzyku. Przykład: sieć użytkowników, serwery, systemy administracyjne, goście, IoT, środowisko produkcyjne i testowe.
Security zone to obszar o określonym poziomie zaufania i regułach dostępu.
Air gap to fizyczna lub logiczna izolacja systemu od innych sieci. Jest stosowana w bardzo wrażliwych środowiskach, ale jest trudna operacyjnie.
Software-Defined Networking (SDN) pozwala zarządzać siecią programowo. Może ułatwiać dynamiczną segmentację, ale wymaga zabezpieczenia warstwy zarządzającej.
Jak to działa krok po kroku
Identyfikujesz typy zasobów.
Grupujesz je według funkcji i ryzyka.
Tworzysz strefy bezpieczeństwa.
Definiujesz dozwolony ruch między strefami.
Blokujesz ruch niepotrzebny.
Monitorujesz przejścia między strefami.
Regularnie sprawdzasz, czy reguły odpowiadają rzeczywistym potrzebom.
Przykład praktyczny
Firma tworzy osobne strefy: użytkownicy, serwery aplikacyjne, bazy danych, administracja, goście Wi-Fi i IoT. Użytkownicy mogą łączyć się z aplikacją, ale nie bezpośrednio z bazą danych. Administratorzy mogą zarządzać serwerami tylko przez jump server. Goście Wi-Fi nie mają dostępu do sieci firmowej.
Przykład egzaminacyjny
Scenariusz
Ransomware na komputerze użytkownika rozprzestrzeniło się na serwery plików i systemy produkcyjne, ponieważ wszystkie systemy były w jednej sieci. Jaka kontrola architektoniczna zmniejszyłaby skutki?
Najlepsza odpowiedź:
Segmentacja sieci.
Z czym nie mylić
Segmentacja nie jest tym samym co backup. Segmentacja ogranicza ruch i skutki kompromitacji. Backup pomaga odtworzyć dane po utracie lub zaszyfrowaniu.
Typowe błędy
Częsty błąd to tworzenie segmentów, ale pozostawianie zbyt szerokich reguł między nimi, np. „any-any”. Drugi błąd to brak dokumentacji ruchu biznesowego. Trzeci błąd to brak monitoringu na granicach segmentów.
Definicja do zapamiętania
Segmentacja dzieli środowisko na strefy i kontroluje ruch między nimi, aby ograniczyć powierzchnię ataku i skutki kompromitacji.
6. Urządzenia i kontrole infrastruktury
Problem
Architektura bezpieczeństwa wymaga właściwego umieszczenia narzędzi. To samo urządzenie może być skuteczne albo prawie bezużyteczne zależnie od miejsca wdrożenia i trybu pracy.
Oficjalne cele SY0-701 w obszarze zabezpieczania infrastruktury wymieniają m.in. device placement, security zones, attack surface, connectivity, fail-open/fail-closed, active/passive, inline/tap, jump server, proxy, IDS/IPS, load balancer, sensors, port security, WAF, UTM, NGFW, Layer 4/Layer 7, VPN, TLS, IPSec, SD-WAN i SASE.
Wyjaśnienie od podstaw
Jump server to kontrolowany serwer pośredni używany do administracji. Administrator nie łączy się bezpośrednio z serwerami produkcyjnymi, tylko przechodzi przez punkt kontrolny, gdzie można wymusić MFA, logowanie sesji i ograniczenia dostępu.
Proxy server pośredniczy w komunikacji. Może filtrować ruch, ukrywać adresy wewnętrzne, wymuszać polityki i logować żądania.
Intrusion Detection System (IDS) wykrywa podejrzany ruch i alarmuje. Intrusion Prevention System (IPS) może aktywnie blokować ruch. IDS jest zwykle detekcyjny, IPS może być prewencyjny.
Load balancer rozdziela ruch między wiele serwerów. Poprawia dostępność i skalowanie, ale sam musi być dobrze zabezpieczony.
Web Application Firewall (WAF) chroni aplikacje webowe przed typowymi atakami aplikacyjnymi, np. injection lub cross-site scripting.
Unified Threat Management (UTM) łączy wiele funkcji bezpieczeństwa w jednym urządzeniu lub usłudze.
Next-Generation Firewall (NGFW) zapewnia bardziej zaawansowaną kontrolę niż klasyczny firewall, np. rozpoznawanie aplikacji, użytkowników i dodatkową inspekcję.
Layer 4 firewall działa głównie na poziomie adresów IP, portów i protokołów transportowych. Layer 7 control rozumie warstwę aplikacyjną, np. HTTP i konkretne żądania.
Jak to działa krok po kroku
Określasz, co chcesz chronić.
Ustalasz, gdzie przebiega ruch.
Dobierasz kontrolę do warstwy problemu.
Decydujesz, czy kontrola ma działać inline, czy w trybie monitorowania.
Ustalasz, czy awaria ma oznaczać fail-open czy fail-closed.
Monitorujesz skuteczność kontroli i stroisz reguły.
Fail-open i fail-closed
Fail-open oznacza, że w razie awarii system pozwala na ruch lub dostęp. To może chronić dostępność, ale zwiększa ryzyko bezpieczeństwa.
Fail-closed oznacza, że w razie awarii system blokuje ruch lub dostęp. To chroni bezpieczeństwo, ale może spowodować przerwę w działaniu.
W pytaniach egzaminacyjnych wybór zależy od priorytetu. System bezpieczeństwa w bardzo wrażliwym środowisku może wymagać fail-closed. System ratujący życie może wymagać dostępności, ale trzeba dodać inne kontrole kompensacyjne.
Inline vs tap/monitor
Inline oznacza, że urządzenie znajduje się na ścieżce ruchu i może go blokować. IPS często działa inline.
Tap/monitor oznacza, że urządzenie obserwuje kopię ruchu i alarmuje, ale zwykle nie blokuje. IDS często działa w takim trybie.
Przykład praktyczny
Firma ma publiczną aplikację webową. Najlepsza architektura może obejmować WAF przed aplikacją, load balancer do rozdzielania ruchu, segmentację między aplikacją a bazą danych, logowanie do SIEM, jump server dla administratorów i ograniczenie dostępu administracyjnego do VPN.
Przykład egzaminacyjny
Scenariusz
Firma chce wykrywać podejrzany ruch bez ryzyka przerwania działania aplikacji. Urządzenie ma otrzymywać kopię ruchu i generować alerty. Co najlepiej pasuje?
Najlepsza odpowiedź:
IDS w trybie tap/monitor.
Z czym nie mylić
Nie myl WAF z klasycznym firewallem sieciowym. WAF rozumie aplikację webową, żądania HTTP i wzorce ataków aplikacyjnych. Firewall Layer 4 może filtrować porty i adresy, ale nie zastępuje WAF przy problemach aplikacyjnych.
Typowe błędy
Częsty błąd to umieszczenie narzędzia w złym miejscu. IDS za niewłaściwym segmentem może nie widzieć istotnego ruchu. WAF nie pomoże aplikacji, jeśli ruch omija WAF. Jump server nie zwiększy bezpieczeństwa, jeśli administratorzy nadal mogą łączyć się bezpośrednio.
Definicja do zapamiętania
Kontrola infrastruktury jest skuteczna tylko wtedy, gdy jest dobrana do warstwy problemu, właściwie umieszczona i działa w odpowiednim trybie: blokującym, monitorującym lub pośredniczącym.
7. Bezpieczna komunikacja i dostęp: VPN, TLS, IPsec, SD-WAN, SASE
Problem
Użytkownicy, aplikacje i oddziały firmy muszą komunikować się przez sieci, które nie zawsze są zaufane. Trzeba chronić poufność, integralność i kontrolę dostępu podczas transmisji.
Wyjaśnienie od podstaw
Virtual Private Network (VPN) tworzy szyfrowany tunel między użytkownikiem lub lokalizacją a siecią organizacji.
Transport Layer Security (TLS) chroni komunikację aplikacyjną, np. HTTPS.
Internet Protocol Security (IPsec) chroni komunikację na poziomie IP i jest często używany w tunelach site-to-site.
Software-Defined Wide Area Network (SD-WAN) programowo zarządza łącznością między lokalizacjami i może wybierać najlepsze ścieżki ruchu.
Secure Access Service Edge (SASE) łączy funkcje sieciowe i bezpieczeństwa jako model dostępu, często chmurowy, przydatny w środowiskach rozproszonych i pracy zdalnej.
Jak to działa krok po kroku
Użytkownik lub lokalizacja potrzebuje dostępu do zasobu.
System sprawdza tożsamość i politykę.
Komunikacja jest tunelowana lub szyfrowana.
Ruch może być filtrowany, logowany i kontrolowany.
Dostęp jest ograniczany do potrzebnych zasobów.
Zdarzenia są monitorowane.
Przykład praktyczny
Pracownik zdalny łączy się z firmą. Zamiast dawać mu pełny dostęp do całej sieci, organizacja może użyć VPN lub SASE z politykami Zero Trust, MFA, oceną urządzenia i dostępem tylko do określonych aplikacji.
Przykład egzaminacyjny
Scenariusz
Firma ma wiele oddziałów i chce centralnie zarządzać trasami ruchu oraz politykami łączności między lokalizacjami. Co najlepiej pasuje?
Najlepsza odpowiedź:
SD-WAN.
Z czym nie mylić
VPN nie jest równoznaczny z pełnym bezpieczeństwem. Jeśli użytkownik po VPN dostaje dostęp do całej sieci, przejęcie jego konta może mieć duże skutki. VPN trzeba łączyć z MFA, segmentacją, politykami dostępu i monitoringiem.
Typowe błędy
Częsty błąd to dopuszczanie split tunneling bez oceny ryzyka. Drugi błąd to brak kontroli urządzeń końcowych. Trzeci błąd to brak logowania sesji zdalnych.
Definicja do zapamiętania
Bezpieczna komunikacja łączy szyfrowanie, tunelowanie, kontrolę tożsamości, polityki dostępu i monitoring, aby chronić ruch między użytkownikami, lokalizacjami i aplikacjami.
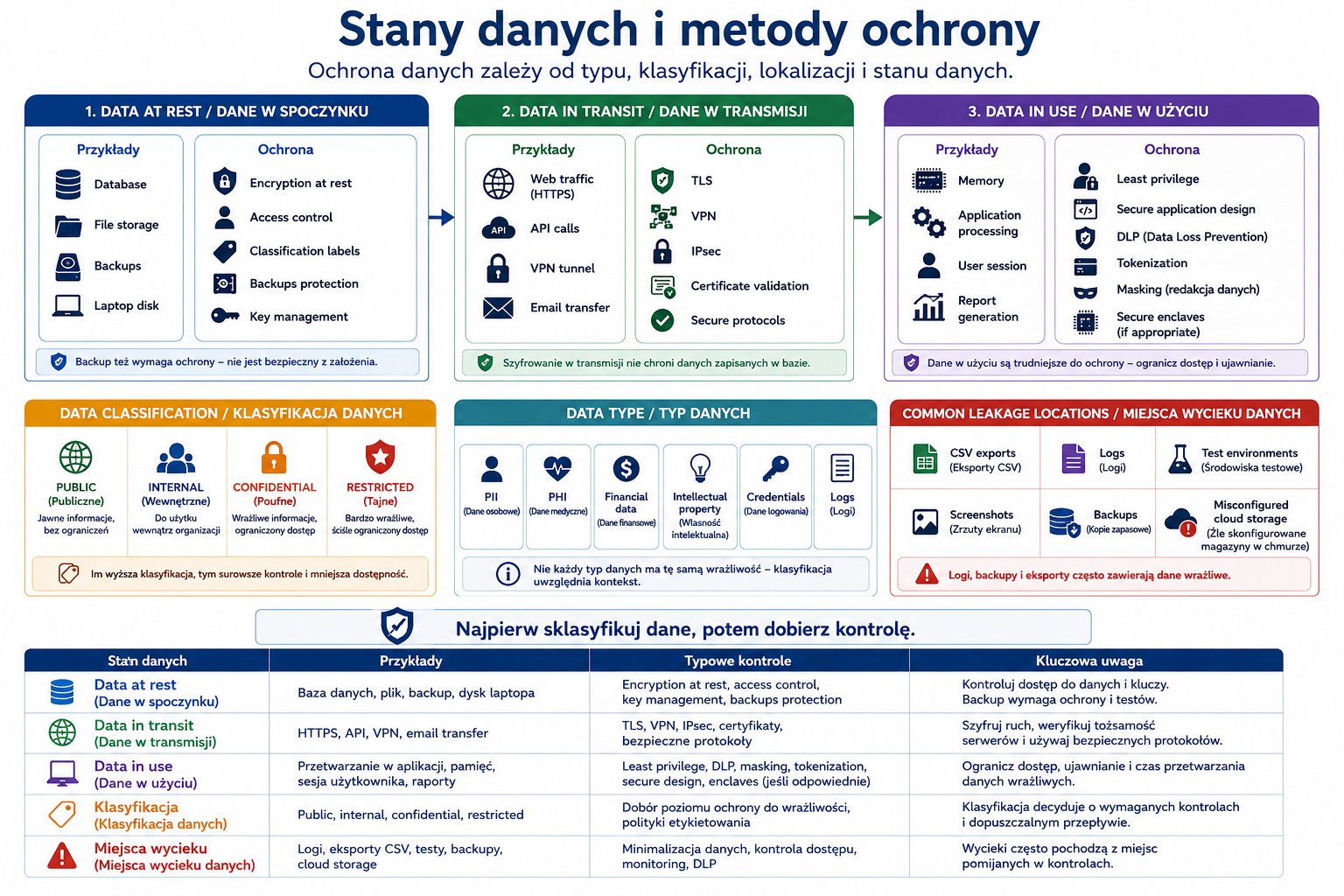
8. Ochrona danych: typy, klasyfikacje i stany danych
Problem
Nie wszystkie dane wymagają takiej samej ochrony. Dane publiczne, finansowe, prawne, prywatne, regulowane, krytyczne i poufne mają różne wymagania. Dodatkowo dane trzeba chronić inaczej, gdy są zapisane, przesyłane lub aktywnie przetwarzane.
Oficjalne cele SY0-701 dla ochrony danych obejmują typy danych, klasyfikacje, stany danych, data sovereignty, geolocation oraz metody ochrony takie jak encryption, hashing, masking, tokenization, obfuscation, segmentation i permission restrictions.
Wyjaśnienie od podstaw
Data classification to przypisanie danych do kategorii ochrony, np. public, private, sensitive, confidential, restricted, critical.
Data at rest to dane zapisane, np. na dysku, w bazie danych lub kopii zapasowej.
Data in transit to dane przesyłane przez sieć.
Data in use to dane aktywnie przetwarzane przez aplikację, proces lub użytkownika.
Data sovereignty oznacza, że dane podlegają prawu i wymaganiom kraju lub regionu, w którym są przechowywane albo przetwarzane.
Jak to działa krok po kroku
Identyfikujesz dane.
Klasyfikujesz je według wrażliwości i wymagań.
Określasz stan danych: at rest, in transit, in use.
Dobierasz ochronę: szyfrowanie, tokenizacja, maskowanie, segmentacja, ograniczenia uprawnień.
Sprawdzasz wymagania lokalizacyjne i regulacyjne.
Monitorujesz dostęp i użycie danych.
Ustalasz retencję i usuwanie danych.
Przykład praktyczny
Numer karty płatniczej w bazie danych może być tokenizowany. W panelu konsultanta może być maskowany jako **** **** **** 1234. Podczas transmisji powinien być chroniony przez TLS. Dostęp do pełnych danych powinien być ograniczony do bardzo wąskiej grupy systemów i użytkowników.
Przykład egzaminacyjny
Scenariusz
Firma chce, aby konsultanci widzieli tylko ostatnie cztery cyfry numeru karty klienta. Która metoda jest najlepsza?
Najlepsza odpowiedź:
Data masking.
Z czym nie mylić
Nie myl masking z encryption. Maskowanie często dotyczy prezentacji danych użytkownikowi. Szyfrowanie chroni dane kryptograficznie. Nie myl tokenization z hashingiem. Token zastępuje wartość i może być mapowany w bezpiecznym systemie, a hash jest skrótem jednokierunkowym.
Typowe błędy
Częsty błąd to ochrona tylko danych w transmisji. Dane mogą wyciec również z bazy, backupu, logów, eksportów CSV, środowisk testowych i raportów. Drugi błąd to brak klasyfikacji, przez co wszystko jest traktowane tak samo albo nic nie jest traktowane wystarczająco poważnie.
Definicja do zapamiętania
Ochrona danych wymaga rozpoznania typu, klasyfikacji, stanu i lokalizacji danych, a następnie dobrania właściwych metod ochrony.
9. Resilience, high availability i disaster recovery
Problem
Bezpieczeństwo obejmuje nie tylko zapobieganie atakom, ale też utrzymanie działania i odtwarzanie po awarii. System może być poufny i integralny, ale jeśli jest niedostępny w krytycznym momencie, organizacja nadal ponosi straty.
Wyjaśnienie od podstaw
Resilience to zdolność systemu lub organizacji do przetrwania awarii, ataku lub zakłócenia i dalszego działania albo szybkiego powrotu do działania.
High availability (HA) oznacza projektowanie systemu tak, aby minimalizować przestoje. Używa się nadmiarowości, load balancingu, klastrów, replikacji i monitoringu.
Disaster recovery (DR) to plan i zdolność odtworzenia systemów po poważnym zdarzeniu.
Load balancing rozdziela ruch między wiele instancji. Clustering łączy systemy tak, aby mogły wspólnie zapewniać dostępność lub przejmować pracę po awarii.
Hot site jest gotowy do szybkiego przejęcia działania. Warm site ma część infrastruktury i wymaga uruchomienia lub synchronizacji. Cold site to lokalizacja podstawowa, która wymaga większego przygotowania przed uruchomieniem.
Oficjalne cele SY0-701 wskazują high availability, load balancing vs clustering, hot/warm/cold sites, geographic dispersion, platform diversity, multi-cloud, continuity of operations, capacity planning, testing, backups, snapshots, recovery, replication, journaling, UPS i generatory jako elementy odporności i odtwarzania.
Jak to działa krok po kroku
Organizacja określa, które systemy są krytyczne.
Ustala wymagania dostępności.
Projektuje nadmiarowość.
Tworzy backupy i replikację.
Przygotowuje alternatywne lokalizacje.
Testuje failover i recovery.
Aktualizuje plan po zmianach architektury.
RTO i RPO
Recovery Time Objective (RTO) odpowiada na pytanie: jak długo system może być niedostępny?
Recovery Point Objective (RPO) odpowiada na pytanie: ile danych maksymalnie można utracić mierzone czasem od ostatniej kopii lub replikacji?
Przykład: RTO = 4 godziny oznacza, że system powinien wrócić w ciągu 4 godzin. RPO = 15 minut oznacza, że organizacja akceptuje utratę maksymalnie około 15 minut danych.
Przykład praktyczny
Sklep internetowy ma duży ruch. Load balancer rozdziela ruch między trzy serwery aplikacji. Baza danych jest replikowana. Backupy są szyfrowane i przechowywane poza główną lokalizacją. Firma testuje failover raz na kwartał. To zwiększa odporność.
Przykład egzaminacyjny
Scenariusz
Firma chce mieć zapasową lokalizację gotową do działania niemal natychmiast, z aktualnymi systemami i danymi. Która opcja najlepiej pasuje?
Najlepsza odpowiedź:
Hot site.
Z czym nie mylić
Backup nie jest tym samym co high availability. Backup pomaga odtworzyć dane, ale niekoniecznie zapewnia ciągłość działania. Load balancing nie jest tym samym co backup. Load balancer poprawia dostępność usługi, ale nie zastępuje kopii danych.
Typowe błędy
Częsty błąd to tworzenie backupów bez testowania odtwarzania. Backup, którego nie da się odtworzyć, nie spełnia swojej roli. Drugi błąd to przechowywanie wszystkich kopii w tej samej lokalizacji lub tej samej domenie administracyjnej. Trzeci błąd to brak szyfrowania backupów.
Definicja do zapamiętania
Resilience to zdolność przetrwania zakłóceń, high availability minimalizuje przestoje, a disaster recovery umożliwia odtworzenie po poważnym zdarzeniu.
Kluczowe pojęcia
| Pojęcie | Znaczenie |
|---|---|
| On-premises | Infrastruktura utrzymywana lokalnie przez organizację. |
| Cloud | Zasoby i usługi dostarczane przez dostawcę chmurowego. |
| Hybrid | Połączenie infrastruktury lokalnej i chmurowej. |
| Shared responsibility model | Podział odpowiedzialności bezpieczeństwa między dostawcę chmury i klienta. |
| Virtualization | Uruchamianie wielu maszyn wirtualnych na jednym hoście. |
| Containerization | Uruchamianie aplikacji w lekkich, izolowanych kontenerach. |
| Serverless | Model, w którym klient wdraża funkcję, a dostawca zarządza warstwą wykonawczą. |
| Microservices | Architektura dzieląca aplikację na wiele małych usług. |
| IoT | Sieciowe urządzenia zbierające dane lub wykonujące działania. |
| ICS/SCADA | Systemy przemysłowe i nadzorcze dla procesów fizycznych. |
| Segmentacja | Podział środowiska na strefy i kontrola ruchu między nimi. |
| Air gap | Izolacja systemu od innych sieci. |
| SDN | Programowo zarządzana sieć. |
| Jump server | Kontrolowany punkt pośredni do administracji. |
| Proxy | Pośrednik w komunikacji, często filtrujący i logujący ruch. |
| IDS | System wykrywania włamań. |
| IPS | System zapobiegania włamaniom. |
| WAF | Firewall chroniący aplikacje webowe. |
| NGFW | Zaawansowana zapora analizująca więcej niż port i adres. |
| VPN | Szyfrowany tunel dostępu. |
| TLS | Protokół ochrony komunikacji aplikacyjnej. |
| IPsec | Mechanizm ochrony komunikacji na poziomie IP. |
| SASE | Model łączący sieć i bezpieczeństwo jako usługę dostępu. |
| Data at rest | Dane zapisane. |
| Data in transit | Dane przesyłane. |
| Data in use | Dane aktywnie przetwarzane. |
| Data sovereignty | Wymogi prawne związane z lokalizacją danych. |
| High availability | Projektowanie minimalizujące przestoje. |
| RTO | Maksymalny akceptowalny czas niedostępności. |
| RPO | Maksymalna akceptowalna utrata danych mierzona czasem. |
| Hot site | Zapasowa lokalizacja gotowa do szybkiego przejęcia działania. |
| Warm site | Lokalizacja częściowo przygotowana. |
| Cold site | Lokalizacja wymagająca znacznego przygotowania. |
Przykłady
Przykład 1: Segmentacja małej firmy
Firma ma użytkowników biurowych, serwer plików, aplikację finansową, Wi-Fi dla gości i kamery IP. Bez segmentacji wszystkie urządzenia mogą się wzajemnie widzieć. Po segmentacji:
- goście Wi-Fi mają tylko Internet
- kamery są w osobnej sieci IoT
- użytkownicy mają dostęp do aplikacji, ale nie bezpośrednio do bazy danych
- administratorzy wchodzą przez jump server
- ruch między segmentami jest logowany.
To zmniejsza skutki przejęcia jednego urządzenia.
Przykład 2: Publiczna aplikacja webowa
Bezpieczniejsza architektura aplikacji może wyglądać tak:
- użytkownik łączy się przez HTTPS
- ruch trafia do WAF
- potem do load balancera
- następnie do serwerów aplikacyjnych
- serwery aplikacyjne łączą się z bazą danych w osobnym segmencie
- administracja jest możliwa tylko przez VPN i jump server
- logi trafiają do centralnego monitoringu.
- Przykład 3: Ochrona danych klientów
Dane klientów są klasyfikowane jako confidential. W bazie są szyfrowane. Podczas transmisji używany jest TLS. W panelu konsultanta część danych jest maskowana. Dostęp jest ograniczony rolami. Backupy są szyfrowane i przechowywane poza główną lokalizacją.
Przykład 4: Odporność sklepu internetowego
Sklep internetowy używa load balancingu, wielu instancji aplikacji, replikacji bazy, backupów poza lokalizacją i testów failover. Dzięki temu awaria jednego serwera nie oznacza całkowitej niedostępności usługi.
Praktyczne zastosowania
Projektowanie prostych stref bezpieczeństwa.
Dobieranie urządzeń i kontroli do miejsca w architekturze.
Ograniczanie skutków ransomware przez segmentację.
Projektowanie bezpiecznego dostępu zdalnego.
Klasyfikowanie danych i dobieranie metod ochrony.
Planowanie backupów, replikacji i odtwarzania.
Przygotowanie do pytań scenariuszowych o „najlepszą architekturę”.
Częste pomyłki
| Pomyłka | Dlaczego jest błędna | Poprawne rozumienie |
|---|---|---|
| „Chmura automatycznie rozwiązuje bezpieczeństwo.” | Klient nadal odpowiada za konfigurację, dane i tożsamości. | Chmura zmienia odpowiedzialność, ale jej nie usuwa. |
| „Kontener to maszyna wirtualna.” | Kontener zwykle współdzieli jądro hosta, VM ma własny system operacyjny. | To różne modele izolacji. |
| „Segmentacja to backup.” | Segmentacja ogranicza ruch, backup odtwarza dane. | Obie kontrole rozwiązują inne problemy. |
| „IDS i IPS to to samo.” | IDS wykrywa, IPS może blokować. | Tryb działania ma znaczenie. |
| „WAF zastępuje poprawę kodu.” | WAF ogranicza ryzyko, ale nie usuwa źródłowego błędu. | Bezpieczne kodowanie nadal jest potrzebne. |
| „VPN daje pełne bezpieczeństwo.” | VPN zapewnia tunel, ale nie zastępuje MFA, segmentacji i monitoringu. | Dostęp zdalny musi być ograniczony politykami. |
| „Backup oznacza high availability.” | Backup pomaga w odtwarzaniu, ale nie minimalizuje automatycznie przestoju. | HA wymaga nadmiarowości i failover. |
| „Hot, warm i cold site różnią się tylko ceną.” | Różnią się gotowością, czasem odtworzenia i kosztem. | Hot jest najszybszy i najdroższy, cold najwolniejszy i tańszy. |
Typowe błędy
Brak segmentacji
Płaska sieć zwiększa skutki kompromitacji jednego hosta.
Złe miejsce kontroli
WAF nie chroni aplikacji, jeśli ruch może go ominąć. IDS nie wykryje ruchu, którego nie widzi.
Nadmierne zaufanie do VPN
Dostęp przez VPN powinien być ograniczony, monitorowany i najlepiej wsparty MFA oraz oceną urządzenia.
Brak testów odtwarzania
Backup bez testu restore jest tylko założeniem, nie potwierdzoną zdolnością.
Brak klasyfikacji danych
Bez klasyfikacji trudno dobrać szyfrowanie, maskowanie, retencję i ograniczenia dostępu.
Niedocenianie systemów legacy, IoT i ICS
Systemy trudne do aktualizacji wymagają architektury kompensacyjnej: segmentacji, kontroli dostępu, monitoringu i okien serwisowych.
Co trzeba umieć na egzamin
W domenie 3.0 trzeba umieć:
- porównać modele architektury i wskazać ich konsekwencje bezpieczeństwa
- rozumieć shared responsibility model
- odróżnić virtualization, containerization, serverless i microservices
- wskazać ryzyka IoT, ICS, SCADA, RTOS i embedded systems
- dobrać segmentację, air gap lub security zones do scenariusza
- dobrać WAF, UTM, NGFW, IDS, IPS, proxy, jump server lub load balancer
- rozumieć fail-open vs fail-closed
- rozumieć inline vs tap/monitor
- dobrać VPN, TLS, IPsec, SD-WAN lub SASE
- rozpoznać data at rest, data in transit i data in use
- dobrać encryption, hashing, masking, tokenization, segmentation albo permission restrictions
- odróżnić load balancing od clusteringu
- odróżnić hot, warm i cold site
- rozumieć backup, snapshot, replication, journaling, UPS i generatory.
Checklista
User powinien umieć:
- Porównać on-premises, cloud i hybrid.
- Wyjaśnić shared responsibility model.
- Odróżnić virtualization, containerization, serverless i microservices.
- Wskazać ryzyka IoT, ICS/SCADA, RTOS i embedded systems.
- Zaprojektować prosty podział na security zones.
- Wyjaśnić, po co stosuje się segmentację.
- Odróżnić IDS od IPS.
- Odróżnić WAF od klasycznego firewalla.
- Wyjaśnić jump server i proxy.
- Wyjaśnić fail-open i fail-closed.
- Odróżnić inline od tap/monitor.
- Dobrać VPN, TLS, IPsec, SD-WAN lub SASE do scenariusza.
- Odróżnić data at rest, data in transit i data in use.
- Dobrać metodę ochrony danych do wymagań.
- Odróżnić high availability, disaster recovery i backup.
- Wyjaśnić RTO i RPO.
- Odróżnić hot, warm i cold site.
- Pytania kontrolne
- Czym różni się on-premises od cloud?
- Co oznacza shared responsibility model?
- Czym różni się maszyna wirtualna od kontenera?
- Dlaczego serverless nie oznacza „braku serwerów”?
- Dlaczego IoT i ICS wymagają szczególnej ochrony?
- Czym różni się segmentacja od air gap?
- Do czego służy jump server?
- Czym różni się IDS od IPS?
- Czym różni się WAF od firewalla Layer 4?
- Co oznacza fail-open?
- Co oznacza fail-closed?
- Kiedy użyć VPN?
- Czym różni się TLS od IPsec?
- Co oznacza data at rest?
- Czym różni się masking od encryption?
- Czym różni się load balancing od clusteringu?
- Czym różni się hot site od cold site?
- Czym różni się RTO od RPO?
- Odpowiedzi z wyjaśnieniami
- On-premises jest utrzymywane lokalnie przez organizację, a cloud korzysta z zasobów dostawcy.
- W on-premises organizacja ma większą bezpośrednią kontrolę, ale też więcej obowiązków operacyjnych.
- Shared responsibility model określa podział odpowiedzialności między dostawcę chmury i klienta.
- Dostawca zabezpiecza część infrastruktury, ale klient nadal odpowiada za dane, konfigurację, uprawnienia i wiele polityk.
- Maszyna wirtualna ma własny system operacyjny, a kontener zwykle współdzieli jądro hosta.
- Kontenery są lżejsze, ale wymagają ochrony obrazów, sekretów i środowiska orkiestracji.
- Serverless oznacza, że klient nie zarządza bezpośrednio serwerami.
- Serwery nadal istnieją, ale są zarządzane przez dostawcę platformy.
- IoT i ICS są często trudne do aktualizacji i mogą wpływać na procesy fizyczne.
- Dlatego ważne są segmentacja, monitoring, kontrola dostępu i zarządzanie dostawcami.
- Segmentacja dzieli środowisko na strefy, a air gap izoluje system od innych sieci.
- Air gap jest bardziej radykalną formą izolacji.
- Jump server jest kontrolowanym punktem pośrednim do administracji.
- Ułatwia logowanie działań, MFA i ograniczenie bezpośredniego dostępu do serwerów.
- IDS wykrywa i alarmuje, IPS może blokować.
- IDS jest zwykle detekcyjny, IPS może działać prewencyjnie.
- WAF chroni aplikacje webowe na poziomie żądań aplikacyjnych, a firewall Layer 4 filtruje głównie adresy, porty i protokoły.
- Fail-open oznacza, że w razie awarii system przepuszcza ruch lub pozwala na działanie.
- Chroni dostępność, ale może zwiększyć ryzyko.
- Fail-closed oznacza, że w razie awarii system blokuje ruch lub dostęp.
- Chroni bezpieczeństwo, ale może przerwać działanie usługi.
- VPN stosuje się do tworzenia szyfrowanego tunelu dostępu przez niezaufaną sieć.
- TLS chroni komunikację aplikacyjną, np. HTTPS, a IPsec chroni komunikację na poziomie IP.
- Data at rest to dane zapisane na dysku, w bazie, backupie lub innym nośniku.
- Masking ukrywa część danych w prezentacji, a encryption szyfruje dane kryptograficznie.
- Load balancing rozdziela ruch między instancje, a clustering łączy systemy w celu wspólnej pracy lub przejęcia działania.
- Hot site jest gotowy do szybkiego przejęcia działania, cold site wymaga dużego przygotowania.
- RTO określa maksymalny czas niedostępności, a RPO maksymalną akceptowalną utratę danych mierzoną czasem.
- Zadania praktyczne
- Laboratorium 1: Zaprojektuj segmentację małej firmy
Cel:
Nauczyć się tworzyć proste security zones.
Kontekst:
Firma ma 40 pracowników, serwer plików, aplikację finansową, Wi-Fi dla gości, kamery IP, drukarki, konta administratorów i publiczną aplikację webową.
Kroki:
- Podziel środowisko na minimum pięć stref bezpieczeństwa.
- Określ, które strefy mogą się komunikować.
- Wskaż, które połączenia powinny być blokowane.
- Dodaj miejsce na jump server.
- Wskaż, gdzie warto zbierać logi.
- Uzasadnij, jak segmentacja zmniejsza skutki kompromitacji.
Oczekiwany rezultat:
Prosty opis stref i dozwolonego ruchu.
Kryteria zaliczenia:
- Wi-Fi dla gości jest odseparowane od zasobów firmowych.
- IoT/kamery są w osobnej strefie.
- Baza danych nie jest dostępna bezpośrednio dla użytkowników.
- Administracja przechodzi przez kontrolowany punkt.
- Ruch między strefami jest ograniczony i monitorowany.
To ćwiczenie wykonuj wyłącznie w legalnym, kontrolowanym środowisku laboratoryjnym. Nie stosuj go wobec cudzych systemów, sieci ani kont.
Laboratorium 2: Dobór kontroli architektonicznych
Cel:
Ćwiczyć dobieranie właściwej kontroli do problemu.
Kontekst:
| Problem | Twoje zadanie |
|---|---|
| Publiczna aplikacja webowa jest narażona na ataki aplikacyjne. | Dobierz kontrolę. |
| Administratorzy łączą się bezpośrednio z serwerami produkcyjnymi. | Dobierz bezpieczniejszy model. |
| Firma chce wykrywać podejrzany ruch bez blokowania. | Dobierz narzędzie i tryb. |
| Firma chce blokować podejrzany ruch inline. | Dobierz narzędzie i tryb. |
| Oddziały firmy potrzebują centralnie zarządzanej łączności. | Dobierz rozwiązanie. |
| Pracownicy zdalni potrzebują dostępu tylko do wybranych aplikacji. | Dobierz model dostępu. |
Kroki:
- Dla każdego problemu wybierz kontrolę.
- Uzasadnij, dlaczego ta kontrola pasuje.
- Wskaż jedną pułapkę lub błąd wdrożeniowy.
- Wskaż, jakie logi lub metryki warto monitorować.
Oczekiwany rezultat:
Tabela problem → kontrola → uzasadnienie → ryzyko wdrożeniowe.
Kryteria zaliczenia:
- Dla aplikacji webowej wskazano WAF.
- Dla administracji wskazano jump server.
- Dla detekcji bez blokowania wskazano IDS/tap.
- Dla blokowania wskazano IPS/inline.
- Dla oddziałów wskazano SD-WAN.
- Dla pracy zdalnej rozważono VPN/SASE z politykami dostępu.
To ćwiczenie wykonuj wyłącznie w legalnym, kontrolowanym środowisku laboratoryjnym. Nie stosuj go wobec cudzych systemów, sieci ani kont.
Laboratorium 3: Plan ochrony danych i odtwarzania
Cel:
Połączyć klasyfikację danych z backupem, szyfrowaniem i RTO/RPO.
Kontekst:
Firma przechowuje dane publiczne, dane pracowników, dane finansowe i dane klientów. Aplikacja sprzedażowa ma działać prawie cały czas. Firma akceptuje maksymalnie 1 godzinę niedostępności i maksymalnie 15 minut utraty danych.
Kroki:
- Sklasyfikuj dane.
- Wskaż, które dane wymagają szyfrowania.
- Wskaż, gdzie zastosować masking lub tokenization.
- Określ RTO i RPO na podstawie scenariusza.
- Zaproponuj backup i replikację.
- Zaproponuj test odtwarzania.
Oczekiwany rezultat:
Krótki plan ochrony danych i odzyskiwania.
Kryteria zaliczenia:
- Dane klientów i finansowe mają wyższy poziom ochrony.
- Uwzględniono encryption at rest i in transit.
- Uwzględniono masking lub tokenization dla danych wrażliwych.
- Poprawnie wskazano RTO = 1 godzina i RPO = 15 minut.
- Uwzględniono test restore/failover.
To ćwiczenie wykonuj wyłącznie w legalnym, kontrolowanym środowisku laboratoryjnym. Nie stosuj go wobec cudzych systemów, sieci ani kont.
Mini-test
Pytanie 1
Firma utrzymuje system finansowy lokalnie, ale używa chmury do aplikacji webowej i backupu. Jaki to model?
A. Wyłącznie on-premises
B. Hybrid
C. Air-gapped
D. Embedded
Poprawna odpowiedź:
B
Wyjaśnienie:
Hybrid łączy środowisko lokalne i chmurowe.
Dlaczego pozostałe odpowiedzi są gorsze:
- A: Nie jest wyłącznie lokalne.
- C: Air gap oznacza izolację od sieci.
- D: Embedded dotyczy systemów wbudowanych.
- Pytanie 2
W chmurze publiczny zasobnik danych został błędnie ustawiony jako dostępny dla wszystkich. Kto najczęściej odpowiada za tę konfigurację?
A. Klient
B. Producent procesora
C. Każdy użytkownik Internetu
D. Dostawca energii
Poprawna odpowiedź:
A
Wyjaśnienie:
W shared responsibility model klient odpowiada za wiele konfiguracji, w tym dostęp do danych i uprawnienia.
Dlaczego pozostałe odpowiedzi są gorsze:
- B i D: Nie dotyczą konfiguracji chmury.
- C: Użytkownicy Internetu nie konfigurują zasobnika.
- Pytanie 3
Które rozwiązanie najlepiej ogranicza skutki kompromitacji jednego komputera w płaskiej sieci?
A. Segmentacja
B. Zmiana tapety
C. Większy dysk
D. Wyłączenie wszystkich logów
Poprawna odpowiedź:
A
Wyjaśnienie:
Segmentacja ogranicza ruch i możliwość rozprzestrzeniania się ataku.
Dlaczego pozostałe odpowiedzi są gorsze:
- B i C: Nie rozwiązują problemu bezpieczeństwa.
- D: Utrudnia wykrywanie i analizę.
- Pytanie 4
Firma chce chronić aplikację webową przed typowymi atakami aplikacyjnymi. Co najlepiej pasuje?
A. WAF
B. UPS
C. Cold site
D. Keylogger
Poprawna odpowiedź:
A
Wyjaśnienie:
Web Application Firewall chroni aplikacje webowe przed wzorcami ataków aplikacyjnych.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: UPS dotyczy zasilania.
- C: Cold site dotyczy odtwarzania.
- D: Keylogger jest złośliwym narzędziem, nie kontrolą.
- Pytanie 5
IDS podłączony do kopii ruchu bez możliwości blokowania działa w jakim trybie?
A. Tap/monitor
B. Fail-closed
C. Tokenization
D. Serverless
Poprawna odpowiedź:
A
Wyjaśnienie:
Tap/monitor oznacza obserwowanie kopii ruchu i alarmowanie bez bezpośredniego blokowania.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Dotyczy zachowania przy awarii.
- C: Dotyczy ochrony danych.
- D: Dotyczy modelu uruchamiania aplikacji.
- Pytanie 6
Który mechanizm jest najlepszy do administracji serwerami przez kontrolowany punkt z logowaniem sesji?
A. Jump server
B. Publiczne konto admin
C. Guest Wi-Fi
D. Cold backup
Poprawna odpowiedź:
A
Wyjaśnienie:
Jump server centralizuje i kontroluje dostęp administracyjny.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Wspólne lub publiczne konto admin zwiększa ryzyko.
- C: Nie dotyczy administracji.
- D: Dotyczy odtwarzania danych.
- Pytanie 7
Dane przesyłane przez sieć to:
- A. Data at rest
- B. Data in transit
- C. Data in use
- D. Data sovereignty
Poprawna odpowiedź:
B
Wyjaśnienie:
Data in transit to dane w trakcie transmisji.
Dlaczego pozostałe odpowiedzi są gorsze:
- A: Dane zapisane.
- C: Dane aktywnie przetwarzane.
- D: Wymogi lokalizacji i prawa.
- Pytanie 8
Konsultant ma widzieć tylko ostatnie cztery cyfry numeru karty. Która metoda pasuje najlepiej?
A. Data masking
B. DDoS
C. Load balancing
D. Fail-open
Poprawna odpowiedź:
A
Wyjaśnienie:
Masking ukrywa część danych w widoku użytkownika.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: To atak na dostępność.
- C: Rozdziela ruch.
- D: Dotyczy zachowania przy awarii.
- Pytanie 9
Firma chce zapasową lokalizację gotową do bardzo szybkiego przejęcia pracy. Co najlepiej pasuje?
A. Hot site
B. Cold site
C. Brak backupu
D. Public Wi-Fi
Poprawna odpowiedź:
A
Wyjaśnienie:
Hot site ma wysoki poziom gotowości i pozwala szybko przejąć działanie.
Dlaczego pozostałe odpowiedzi są gorsze:
- B: Cold site wymaga dużo przygotowania.
- C: Brak backupu zwiększa ryzyko.
- D: Nie dotyczy odtwarzania.
- Pytanie 10
RPO oznacza:
- A. Maksymalny akceptowalny czas niedostępności
- B. Maksymalną akceptowalną utratę danych mierzoną czasem
- C. Liczbę administratorów
- D. Typ firewalla aplikacyjnego
Poprawna odpowiedź:
B
Wyjaśnienie:
Recovery Point Objective określa, ile danych organizacja może maksymalnie utracić, mierzone czasem od ostatniego punktu odzyskiwania.
Dlaczego pozostałe odpowiedzi są gorsze:
- A: To RTO.
- C i D: Nie dotyczą RPO.
- Fiszki
| Przód fiszki | Tył fiszki |
|---|---|
| Co oznacza on-premises? | Infrastruktura utrzymywana lokalnie przez organizację. |
| Co oznacza cloud? | Usługi i zasoby dostarczane przez dostawcę chmurowego. |
| Co oznacza hybrid? | Połączenie środowiska lokalnego i chmurowego. |
| Co oznacza shared responsibility model? | Podział odpowiedzialności bezpieczeństwa między dostawcę chmury i klienta. |
| VM vs container? | VM ma własny system operacyjny; kontener zwykle współdzieli jądro hosta. |
| Co oznacza serverless? | Klient wdraża funkcję, a dostawca zarządza warstwą serwerową. |
| Co to są microservices? | Architektura dzieląca aplikację na małe usługi. |
| Co oznacza IoT? | Sieciowe urządzenia zbierające dane lub wykonujące działania. |
| Co oznacza ICS/SCADA? | Systemy przemysłowe i nadzorcze sterujące procesami fizycznymi. |
| Co robi segmentacja? | Dzieli środowisko i ogranicza ruch między strefami. |
| Co to jest air gap? | Izolacja systemu od innych sieci. |
| Co to jest jump server? | Kontrolowany punkt pośredni do administracji. |
| IDS vs IPS? | IDS wykrywa, IPS może blokować. |
| Co robi WAF? | Chroni aplikacje webowe przed atakami aplikacyjnymi. |
| Co oznacza NGFW? | Next-Generation Firewall z zaawansowaną inspekcją i kontrolą. |
| Fail-open vs fail-closed? | Fail-open przepuszcza przy awarii; fail-closed blokuje przy awarii. |
| Inline vs tap/monitor? | Inline jest na ścieżce ruchu; tap/monitor obserwuje kopię. |
| Co robi VPN? | Tworzy szyfrowany tunel dostępu. |
| TLS vs IPsec? | TLS chroni aplikacyjnie, IPsec na poziomie IP. |
| Co oznacza SASE? | Model łączący sieć i bezpieczeństwo jako usługę dostępu. |
| Data at rest? | Dane zapisane. |
| Data in transit? | Dane przesyłane. |
| Data in use? | Dane aktywnie przetwarzane. |
| Co oznacza data sovereignty? | Dane podlegają wymaganiom kraju lub regionu. |
| Masking vs encryption? | Masking ukrywa część danych; encryption szyfruje kryptograficznie. |
| Load balancing vs clustering? | Load balancing rozdziela ruch; clustering zapewnia wspólną pracę lub przejęcie. |
| Hot site vs cold site? | Hot jest gotowy szybko; cold wymaga przygotowania. |
| RTO vs RPO? | RTO to czas niedostępności; RPO to utrata danych mierzona czasem. |
Obrazy do wygenerowania
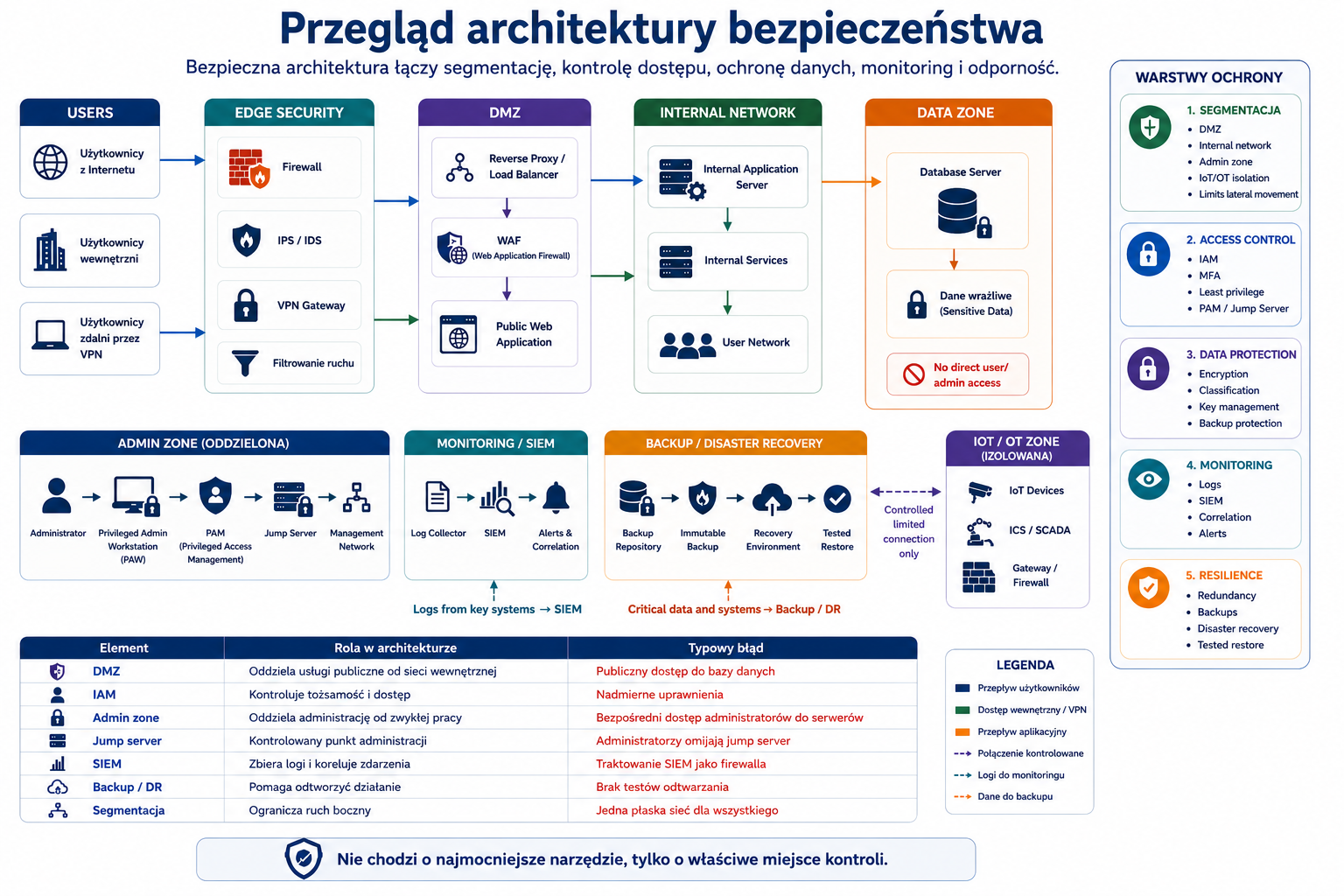
IMG_M03_S01_SECURE_ARCHITECTURE_OVERVIEW
Miejsce w materiale:
Sekcja „Wprowadzenie”.
Cel obrazu:
Pokazać wysokopoziomowy model bezpiecznej architektury przedsiębiorstwa.
Opis obrazu do wygenerowania:
Diagram architektury z użytkownikami, Internetem, WAF, load balancerem, serwerami aplikacyjnymi, bazą danych, segmentem administracyjnym z jump serverem, segmentem IoT, chmurą, VPN/SASE dla pracy zdalnej i centralnym systemem logowania. Pokaż granice security zones i strzałki dozwolonego ruchu.
Styl:
Architektura systemu / diagram techniczny.
Elementy obowiązkowe:
- użytkownicy
- Internet
- WAF
- load balancer
- serwery aplikacyjne
- baza danych
- jump server
- VPN/SASE
- segment IoT
- cloud
- log monitoring
- security zones.
Elementy, których unikać:
- zbyt wielu podsieci
- nieczytelnych ikon
- losowych symboli hakerskich
- realistycznych danych firmowych.
- IMG_M03_S02_COMPUTE_MODELS_COMPARISON
Miejsce w materiale:
Sekcja „Virtualization, containerization, serverless i microservices”.
Cel obrazu:
Porównać modele uruchamiania aplikacji.
Opis obrazu do wygenerowania:
Tabela wizualna porównująca virtualization, containerization, serverless i microservices. Dla każdego modelu pokaż: poziom izolacji, kto zarządza infrastrukturą, główne zalety, główne ryzyka bezpieczeństwa. Użyj krótkich etykiet, np. „VM = full OS”, „container = shared kernel”, „serverless = function”, „microservices = many small services”.
Styl:
Infografika techniczna / tabela porównawcza.
Elementy obowiązkowe:
- virtualization
- containerization
- serverless
- microservices
- izolacja
- odpowiedzialność
- ryzyka
- zalety.
Elementy, których unikać:
- długich akapitów
- szczegółów vendor-specific
- kodu.
- IMG_M03_S03_ENTERPRISE_SECURITY_ZONES
Miejsce w materiale:
Sekcja „Urządzenia i kontrole infrastruktury”.
Cel obrazu:
Pokazać segmentację i umiejscowienie kontroli.
Opis obrazu do wygenerowania:
Diagram sieci z security zones: guest Wi-Fi, user zone, server zone, database zone, admin zone, IoT zone i DMZ/public app zone. Dodaj WAF przed aplikacją webową, firewall między strefami, IDS w trybie monitor, IPS inline, jump server w admin zone, proxy dla ruchu wychodzącego i SIEM/logging jako centralny odbiorca logów.
Styl:
Diagram sieci / architektura bezpieczeństwa.
Elementy obowiązkowe:
- security zones
- DMZ/public app
- WAF
- firewall
- IDS
- IPS
- jump server
- proxy
- database zone
- IoT zone
- SIEM/logging.
Elementy, których unikać:
- publicznych adresów IP
- zbyt szczegółowych reguł firewall
- instrukcji ofensywnych.
- IMG_M03_S04_DATA_STATES_AND_PROTECTION
Miejsce w materiale:
Sekcja „Ochrona danych”.
Cel obrazu:
Pokazać trzy stany danych i właściwe metody ochrony.
Opis obrazu do wygenerowania:
Diagram z trzema kolumnami: data at rest, data in transit, data in use. Przy data at rest pokaż database, disk, backup oraz encryption/access control. Przy data in transit pokaż network/TLS/VPN. Przy data in use pokaż application/user/process oraz permission restrictions, masking, monitoring. Dodaj boczną sekcję: data sovereignty/geolocation.
Styl:
Infografika edukacyjna / schemat blokowy.
Elementy obowiązkowe:
- data at rest
- data in transit
- data in use
- encryption
- TLS/VPN
- masking
- tokenization
- permission restrictions
- data sovereignty.
Elementy, których unikać:
- nadmiaru tekstu
- wzorów kryptograficznych
- niejasnych ikon.
- IMG_M03_S05_RESILIENCE_RECOVERY_MAP
Miejsce w materiale:
Sekcja „Resilience, high availability i disaster recovery”.
Cel obrazu:
Pokazać różnicę między wysoką dostępnością, backupem i odtwarzaniem.
Opis obrazu do wygenerowania:
Mapa pojęć: high availability → load balancing, clustering, failover; backups → onsite/offsite, encryption, snapshots, frequency; disaster recovery → hot site, warm site, cold site, recovery testing; power → UPS, generators. Dodaj małą ramkę: RTO = jak szybko wrócić, RPO = ile danych można utracić.
Styl:
Mapa pojęć / diagram edukacyjny.
Elementy obowiązkowe:
- high availability
- load balancing
- clustering
- failover
- backup
- snapshots
- replication
- hot/warm/cold site
- UPS
- generators
- RTO
- RPO.
Elementy, których unikać:
- skomplikowanej architektury centrum danych
- mało czytelnych strzałek
- zbyt wielu skrótów bez rozwinięcia.
- Pokrycie wymagań egzaminacyjnych
| Wymaganie egzaminacyjne SY0-701 | Gdzie jest omówione | Poziom pokrycia | Uwagi |
|---|---|---|---|
| 3.1 Compare and contrast security implications of different architecture models | Modele architektury; chmura; virtualization; containerization; IoT/ICS/SCADA | Pełny | Uwzględniono modele i konsekwencje bezpieczeństwa. |
| 3.2 Given a scenario, apply security principles to secure enterprise infrastructure | Segmentacja; urządzenia infrastruktury; secure communication/access | Pełny | Uwzględniono placement, zones, fail-open/closed, IDS/IPS, WAF, VPN, SD-WAN i SASE. |
| 3.3 Compare and contrast concepts and strategies to protect data | Ochrona danych | Pełny | Uwzględniono typy danych, klasyfikacje, stany danych, sovereignty i metody ochrony. |
| 3.4 Explain the importance of resilience and recovery in security architecture | Resilience, HA i disaster recovery | Pełny | Uwzględniono HA, sites, backupy, replication, journaling, UPS, generatory i testy. |
Co warto powtórzyć przed przejściem dalej
On-premises vs cloud vs hybrid.
Shared responsibility model.
VM vs container vs serverless.
Segmentacja i security zones.
WAF vs firewall Layer 4.
IDS vs IPS.
Inline vs tap/monitor.
Fail-open vs fail-closed.
VPN vs TLS vs IPsec.
Data at rest vs in transit vs in use.
Masking vs tokenization vs encryption.
High availability vs disaster recovery vs backup.
Hot site vs warm site vs cold site.
RTO vs RPO.
Kontrola kompletności modułu
Zakres z konspektu pokryty:
- modele infrastruktury: on-premises, cloud, hybrid
- virtualization, containerization, serverless, microservices
- IoT, ICS, SCADA, RTOS i embedded systems
- segmentacja, security zones, air gap, SDN
- urządzenia infrastruktury: WAF, UTM, NGFW, IDS/IPS, proxy, jump server, load balancer
- bezpieczna komunikacja: VPN, TLS, IPsec, SD-WAN, SASE
- ochrona danych: typy, klasyfikacje, stany, sovereignty, encryption, masking, tokenization
- odporność i odtwarzanie: HA, backup, replication, journaling, hot/warm/cold sites, UPS i generatory
- ćwiczenia, mini-test, fiszki, obrazy i kontrola pokrycia wymagań.
Zakres wymagający pogłębienia:
- konkretne reguły firewall i access lists będą rozwijane w Security Operations.
- szczegółowy IAM i federation pojawią się w Security Operations I.
- szczegółowy backup, BIA, RTO i RPO wrócą w Security Program Management and Oversight.
- monitoring, SIEM i analiza logów będą rozwinięte w Security Operations II.
Najważniejsze rzeczy do zapamiętania:
- Architektura decyduje, gdzie umieszczasz kontrole i jak ograniczasz skutki awarii lub kompromitacji.
- Chmura nie usuwa odpowiedzialności klienta.
- Segmentacja jest jedną z najważniejszych kontroli ograniczających skutki ataku.
- Narzędzie bezpieczeństwa musi być właściwie umieszczone.
- Dane trzeba chronić według typu, klasyfikacji, stanu i lokalizacji.
- Backup, high availability i disaster recovery to różne pojęcia.
- RTO mówi „jak szybko wrócić”, RPO mówi „ile danych można utracić”.
Czy materiał wystarcza do opanowania tej części:
Tak, jako pełne wprowadzenie do domeny 3.0 Security Architecture na poziomie od zera do egzaminacyjnego.
Potencjalne luki:
- Przyda się dodatkowa powtórka z pytań scenariuszowych o dobór WAF/IDS/IPS/NGFW/proxy.
- Przyda się dodatkowe ćwiczenie z RTO/RPO po module o Business Impact Analysis.
- Warto wrócić do segmentacji przy module o ransomware i incident response.
Rekomendowana powtórka:
- Przerób fiszki.
- Rozwiąż mini-test bez patrzenia w odpowiedzi.
- Wykonaj laboratorium 1 i 2.
- Narysuj własny diagram małej firmy z minimum pięcioma security zones.
- Dla każdego ważnego systemu zapisz: dane, dostęp, segment, monitoring, backup, RTO/RPO.
- Kontrola głębokości wyjaśnień
- Ważne pojęcia zostały rozwinięte, a nie tylko wymienione.
- Przy każdym kluczowym obszarze pokazano problem, mechanizm, przykład praktyczny, scenariusz egzaminacyjny, częste pomyłki i definicję.
- Dodano ćwiczenia, checklistę, pytania kontrolne, odpowiedzi, mini-test, fiszki i opisy obrazów.
- Ćwiczenia są defensywne i przeznaczone wyłącznie do legalnego, kontrolowanego środowiska.
- Struktura odpowiada wymaganiom generowania właściwego materiału szkoleniowego.